Estructura de datos: introducción

Las estructuras de datos, junto con el estudio de algoritmo, hacen parte de los fundamentos de la programación y se escucha mucho sobre la importancia de estudiar este tema. En esto articulo, vamos abordar las estructuras de datos: que son, algunos ejemplos y porque son importantes.
¿que son los datos?
Los datos son los bloques básicos de la programación. Ellos representan una unidad o un elemento de información que puede ser accedido a través de un identificador, por ejemplo, una variable.
La mayor parte de los lenguajes de programación trabaja con variaciones baseadas en los cuadros tipos primitivos abajo:
- INT o numero entero: valores numéricos enteros (positivos o negativos);
- FLOAT o el llamado "punto fluctuante" : valores numéricos con decimales (positivos o negativos);
- BOOLEAN o booleanos: representando apenas por dos valores, "verdadero" o "falso". También llamado de operadores lógicos;
- TEXT: secuencia o cadenas de carácter, utilizados para manipular textos y/o otros tipos de datos no numéricos o booleanos, como hashes de criptografía.
En JavaScript, por ejemplo, tenemos tipos primitivos construidos en la estructura básica del lenguaje: number, string, boolean y symbol (de "nombre simbólico", utilizado entre otras cosas para crear propriedades únicas en objetos). Ya C# (C-Sharp) trabaja con una cantidad mayor de tipos primitivos, de acuerdo con el espacio de memoria que será ocupado por la variable: Boolean, Byte, SByte, Int16, UInt16, Int32, UInt32, Int64, UInt64, IntPtr, UIntPtr, Char, Double y Single. C, por su vez, no tiene un tipo proprio de dato booleano; false es representado por el numero 0 y cualquier otro alguarismo representa true. Otras lenguaje pueden trabaja con otras variaciones.
¿que son las estructura de datos?
En computación, normalmente utilizamos los datos de forma conjunta. La forma como estos datos serán agregados y organizados depende mucho de como serán utilizados y procesados, considerando, por ejemplo, la eficiencia para buscar, el volumen de datos trabajados, la complejidad de implementación y la forma como los datos se relacionan. Estas formas de organización son las llamadas estructuras de datos.
Podemos afirmar que un programa es compuesto de algoritmos y estructuras de datos, que juntos hacen que el programa funcione correctamente.
Cada estructura de datos tiene un conjunto de métodos propios para realizar operaciónes como:
- Agregar o quitar elementos;
- Buscar y localizar elementos;
- Ordenar (clasificar) elementos de acuerdo con alguna orden especificada.
Característica de las estructuras de datos
Las estructuras de datos pueden ser:
- Lineales (ej. arrays) o no lineales (ej. grafos);
- Homogéneas (todos los datos que componen la estructura son del mismo tipo) o heterogéneas (pueden contener datos de varios tipos);
- Estáticas (tiene tamaño/capacidad de memoria fija) o dinámicas (pueden expandir).
Vamos a especificar una lista y descripción de algunas estructuras:
Array
También llamado de vector o matriz , el array es la estructura de datos más comum y normalmente es la primera que estudiamos.
Un array es una lista ordenada de valores:
const listaNumeros = [4, 6, 77, 1, 0];
const listaFrutas = ["banana", "manzana", "pera"];Por ordenada, se entiende como una lista donde siempre se accede a los valores en el mismo orden. O sea, a no ser que sea utilizada alguna función o metodo para alterar la orden, el primer elemento del array listaNumeros siempre sera 4, y el ultimo, 0.
Normalmente se trabaja solo con un tipo de dato por array; Aunque JavaScript permita la declaración de arrays de más de un tipo de dato, por ejemplo ["banana", 5, true], eso no acontece la mayoria de lenguajes de programación.
Por tratarse de una estructura de datos básica y muy utilizada, los lenguajes de programación suelen tener ya implementado este tipo, con métodos nativos de creación y manipulación de arrays. En el caso de JavaScript, puede buscar los métodos de matriz y los constructores en MDN.
Usos
Al ser la estructura más común, las matrices se utilizan prácticamente en todas las situaciones que implican la organización de datos del mismo tipo; ya sean datos recibidos por una API o enviados a una base de datos, o incluso pasados a través de parámetros a una función o método. Los arreglos también pueden ser multidimensionales, se utiliza siempre que existe la necesidad de tabular datos y se utilizan matrices (matrices) bidimensionales para el procesamiento de imágenes.
Pila
En una matriz, es posible utilizar sus propias funciones para manipular elementos en cualquier posición de la lista. Sin embargo, hay situaciones (veremos ejemplos más adelante) donde es deseable un mayor control sobre las operaciones que se pueden realizar en la estructura. Aquí es donde entra en juego la implementación de estructuras de datos como la pila (stack) y la cola (queue).
La pila es una estructura de datos que, al igual que la matriz, es similar a una lista. El paradigma principal detrás de la pila es LIFO - Last In, First Out, o "el último en entrar es el primero en salir", en traducción libre.
Para comprender mejor lo que esto significa, piense en una pila de libros o platos. Al apilar libros, por ejemplo, el primer libro que se quita de la pila es necesariamente el último que se coloca; si tratamos de quitar el último libro de la pila, todo se derrumbará. Es decir, el último libro que se apila es el primero que se retira.
Abstrayendo este principio al código, resulta que solo hay dos métodos posibles para manipular los datos en una pila:
- insertar un elemento en la parte superior de la pila
- eliminar un elemento de la parte superior de la pila.
A diferencia de la matriz, los lenguajes de programación generalmente no tienen métodos nativos para crear y manipular pilas. Sin embargo, es posible usar métodos de matriz para implementar pilas.
Usos
El caso de uso más famoso de la pila es la call stacks o pila de llamadas de un programa que se está ejecutando: el orden de ejecución de los procesos "llamados" por un programa a través de funciones o métodos obedece al principio de la pila.
Otro recurso que usamos todos los días y que usa pilas para funcionar es el mecanismo de “atrás” y “adelante” de las páginas del navegador (generalmente representado por flechas hacia la izquierda y hacia la derecha). Las direcciones visitadas se siguen acumulando; cuando llamamos a la función de "retorno", la última dirección visitada, es decir, la que está en la parte superior de la pila, es el primero que se muestra.
Cola
La cola tiene una estructura similar a la pila, pero con una difirencia concectual importante: el paradigma por tras de la cola es el FIFO - First In, First Out, o "el primero en entrar es el primero en salir", en traducción libre.
Piense en una cola para comprar boletos, por ejemplo. La persona que llegó primero será atendida (y comprará su boleto) antes de aquellas que llegaron más tarde y se quedaron atrás en la fila. La cola como estructura de datos sigue el mismo principio.
Por lo tanto, también hay solo dos formas de manipular una cola:
- Insertar un elemento al final de la cola
- Remover un elemento del inicio de la cola
Deque
La estructura de datos deque (abreviación de double-ended queue o "cola de dos puntos") es una variación de la cola que acepta la inserción y eliminación de elementos tanto del principio como del final de la cola.
Podemos comparar, nuevamente, con una cola de personas en un mostrador de servicio: primero se atiende a una persona mayor que llega (o sea, no puede ser colocada en el final de la cola), al mismo tiempo que una persona que entro en el final de la cola puede desistir de esperar y irse (en este caso, no puedes esperar la persona llegar al frente de la cola para luego quitarla).
Otra forma de entender la estructura deque es como una unión de estructuras de pila y cola.
Cola circular
Otra variación de cola es la cola circular (circular queue) , donde el ultimo elemento es conectado con el primer elemento - como en el circulo:

La cola circular busca resolver una limitación de cola lineal, que es lidear con espacios vazios que pueden hacer cola despues de quitar elementos del inicio de la cola.
Usos
Un uso fácil de recordar para la cola es simplemente la cola de impresión de los sistemas operativos: el último trabajo de impresión que se agregará a la cola será el último en imprimirse.
Además, las solicitudes que se hacen a un servidor también se organizan en una cola para ser respondidas, y cuando cambiamos de programa usando el atajo alt+tab, el sistema operativo gestiona el pedido utilizando el principio de lista circular.
Lista enlazada
Ya vimos que la mayoria de las lenguajes de programación tiene metodos nativos para la manioulación de arrays, como por ejemplo insertar y remover elementos. Adémas, estos metodos hacen una buena parte del trabajo de ordenar y buscar elementos por nosotros..
Pero, hay tres cosas importantes para saber sobre arrays:
- En la mayor parte de las lenguajes de programación, los arrays tienen tamaños fijos;
- Todos los elementos ocupan espacios sequenciales en la memoria;
- Insertar o remover elemento del medio del array no es muy sencillo, porque necesita que elementos sean desplazados. Por ejemplo:
// 0 1 2 3
[46, 34, 76, 12]
// removiendo 76, el elemento 12 pasa a ocupar el índice 2
// 0 1 2
[46, 34, 12]// 0 1 2 3
[46, 34, 76, 12]
// añadiendo 25, el elemento 12 pasa a ocupar el índice 4
// 0 1 2 3 4
[46, 34, 76, 25, 12]Este trabajo de desplazar elementos es hecho internamente por los metodos nativos del array que los lenguajes ya tienen y utilizamos en el dia a dia, por eso normalmente no nos fijamos. Pero, esta en la implementación del metodo hecho en el codigo fuente del lenguaje.
Al igual que los arrays, las listas enlazadas también almacenan elementos secuencialmente, sin embargo, en lugar de almacenar elementos contiguos en la memoria, como en los arreglos, las listas enlazadas no dependen de este tipo de organización. Utilizan punteros para vincular elementos, y cada elemento "apunta" a la dirección de memoria del siguiente en la lista, sin necesidad de estar en el siguiente bloque de memoria.
De esta forma, cuando se trabaja con listas enlazadas, tampoco es necesario desplazar elementos al incluir o eliminar, considerando que, cada vez que se realiza este desplazamiento en un arreglo, es necesario reposicionar los elementos en nuevos espacios de memoria. Cada "nodo" en la lista apunta al puntero de memoria donde se encuentra el siguiente elemento, independientemente de dónde se encuentre ese espacio de memoria.
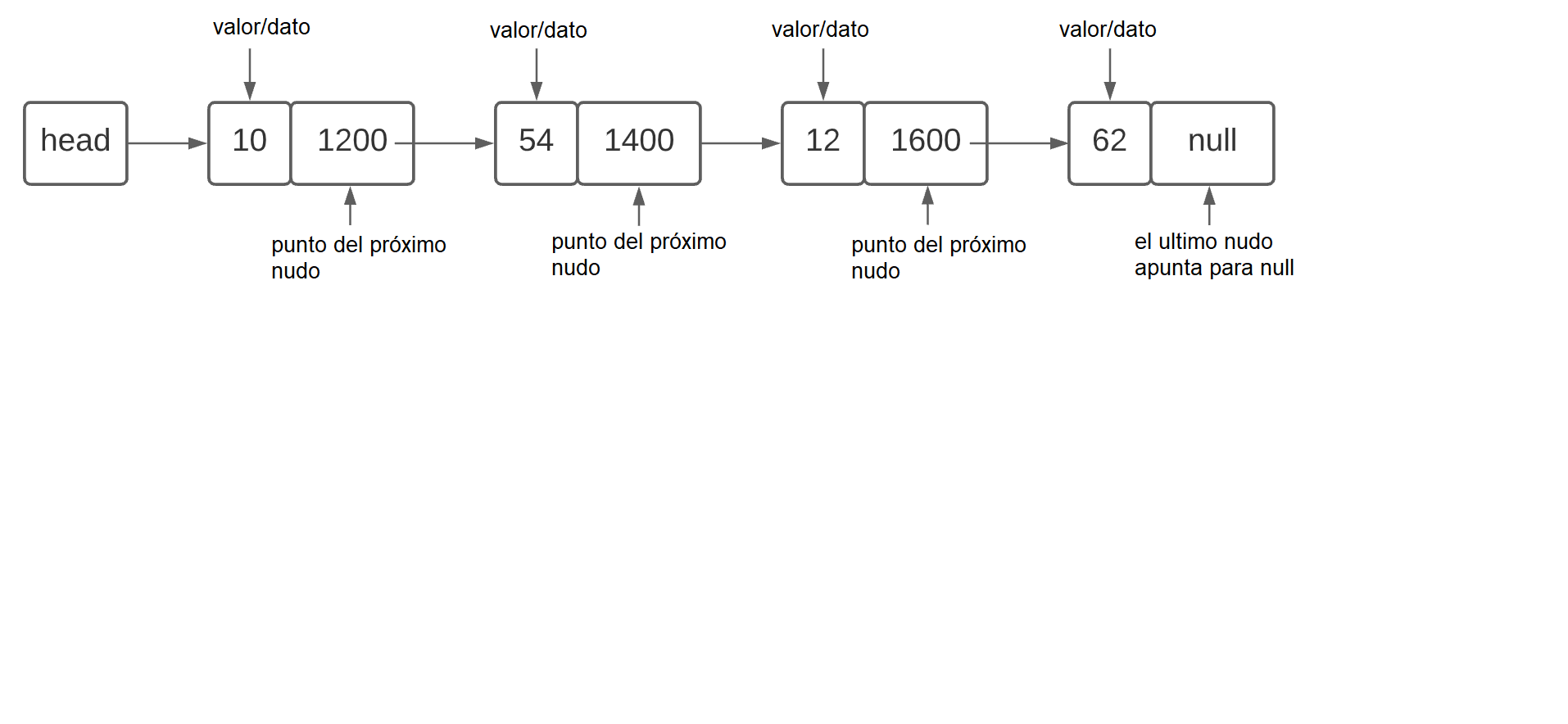
Usos
Recordando que la lista vinculada, vincula elementos que apuntan a la ubicación del siguiente elemento en la memoria, los programas de "álbum de fotos" (vista de imagen) utilizan la lista vinculada para vincular los archivos de imagen y "llamar" a la imagen siguiente/volver a la imagen anterior a través de flechas del teclado o botones “anterior” y “siguiente”. El mismo principio se aplica a las listas de reproducción de música o vídeo.
Conjunto
La estructura de datos conjunto (o set) es una lista no ordenada de elementos unico. O sea, no es posible repetir el valor de un elemento dentro de un conjunto.
Por ejemplo, es perfectamente posible crear un array con los seguintes elementos:
const lista = [1, 1, 1, 3, 5, 7, 9]Pero, en un conjunto, no es posible repetir valores, no importa la orden de los elementos. La mayor parte de las lenguajes de programación más utilizadas tiene metodos nativos para creación de conjuntos. En el caso del JavaScript:
const lista = [1, 1, 1, 3, 5, 7, 9];
const conjunto = new Set(lista);
console.log(conjunto);
//set(5) {1, 3, 5, 7, 9}Usos
Como habrás imaginado, la estructura de conjuntos proviene de las matemáticas, y también es posible realizar operaciones como unión e intersección en conjuntos de datos. Uno de los usos más comunes de esta estructura es en bases de datos SQL.
Diccionario o hashmap
Diccionario (también conocido como mapa, map o hashmap) es una estructura que conservar los datos en pares de llave y valor y utilizar estas llave para encontrar los elementos asociados a ellas, diferentemente de las estructuras que vimos hasta ahora, que trabajan con listas (sequencias o no) apenas de valores.
Esta descripción se parece mucho a otra estructura que ya conocemos, el objeto. Pero hay varias diferencias entre diccionarios, mapas y objetos. Por ejemplo, es posible mapear el tamaño de un diccionario (es decir, el número de pares clave, valor) y los diccionarios pueden aceptar cualquier tipo de datos como clave (los objetos solo aceptan cadenas o símbolos). Los diccionarios también pueden funcionar mejor cuando buscan y manipulan datos que objetos, ya que usan referencias a claves; de manera similar a los punteros, las claves apuntan a la dirección de memoria de sus valores.
Un aspecto importante sobre diccionarios vs objetos: la decisión sobre cual utilizar va depender mucho del lenguaje. Cada lenguaje implementa sus propios metodos para creación de instancia de objetos o diccionario y para manipulación de datos. Por ejemplo, diccionario en Python no eran ordenados por padrón hasta la versión 3.6, ya el objetivo
Map()en JavaScript es ordenado por padrón; otras lenguajes pueden tener suporte a diccionarios, pero no a objetos.
Usos
El formato llave:valor del diccionario es el más común para tratar datos almacenados en bases de datos, pero no sólo para eso: el formato se utiliza siempre que se necesita asociar datos y referencias para su posterior consulta,
ya sea información de la base de datos de un producto o incluso la relación entre el nombre de un archivo y su ruta interna en la memoria de la computadora, hecha por el sistema operativo.
Árbol
El árbol es una estructura no lineal, muy util para almazenar datos de forma jerárquica y que poden ser acesados de forma rapida.
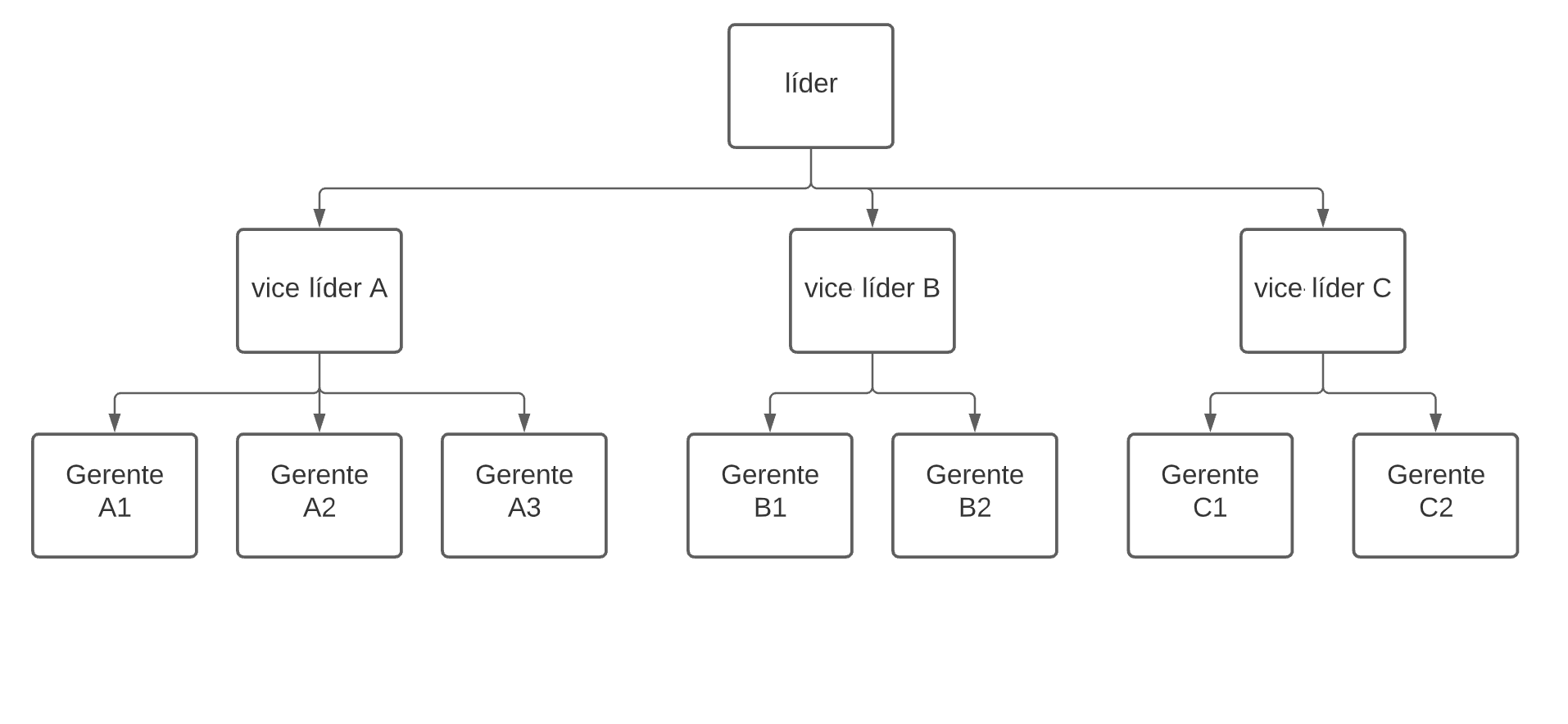
Un árbol se puede definir como una colección de datos representados por nodos y organizados en niveles jerárquicos (en lugar de secuencias como las estructuras vistas anteriormente).
Un ejemplo de estructura en árbol son los organigramas de empresas:
La estructura más comun es de árbol binaria, que tiene en el maximo dos nodos hijos a partir del nodo inicial (llamado de raiz o root). Un nodo puede tener padres, hermanos e hijos; los nodos que tienen por lo menos un hijo son llamados de nodos internos y los nodos sin hijos son llamados de externos o hojas:
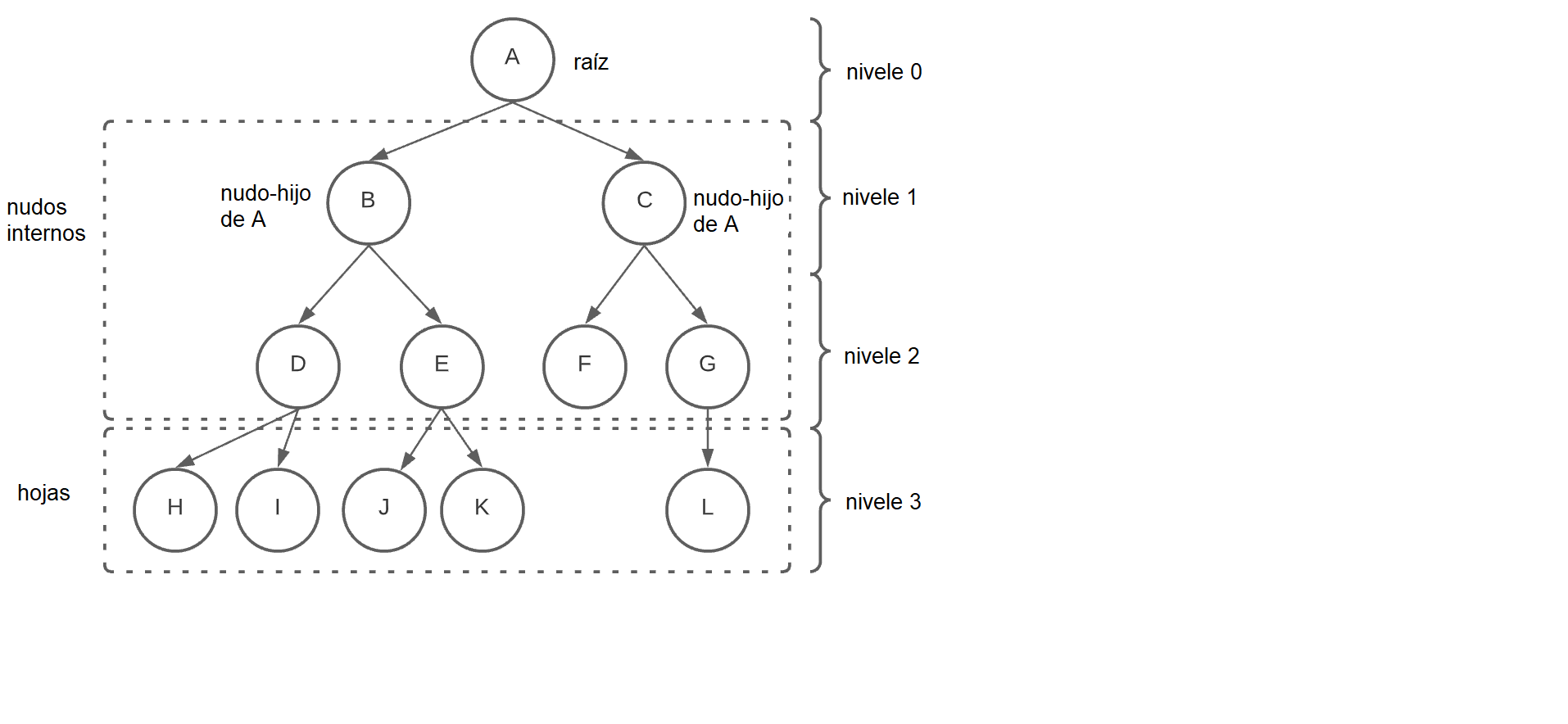
A partir de la estructura de árbol binaria (con un nodo hijo a la izquierda y uno a la derecha de la raiz) es posible estructurar la llamada BST, o árbol de busqueda binaria (binary search tree), que utiliza el principio del algoritmo de busqueda binaria para estructurar los datos de forma que los valores menores esten a la izquierda de la raiz y valores mayores a la derecha. Esta unión del algoritmo con la estructura de datos lleva una mayor eficiencia en la manipulación de datos, sea para buscar, alterar, insertar o remover elementos.
Heap binario
El heap binario es un tipo especial de árbol binaria, normalmente utilizada en computación para implementar cola de prioridades, porque en un heap puedes extraer de forma más eficiente el valor minimo o maximo de una lista. Puedes traducir heap, muy libremente, como un "grupo" o "porción" de datos.
El heap binario difiere del árbol binario en dos caracteristicas principales:
- Todos los niveles, con excepción del ultimo, tiene hijos tanto en la izquierda como en la derecha de la raíz. En el ultimo nivel, los hijos se posicionan lo más a la izquierda posible. Es lo que llamamos árbol completa.
- Puede ser un heap minimo (min heap), para extraer el menor valor del árbol, o heap maximo (max heap) para extraerse el mayor valor. Todos los nodos deben ser o
>=(en el caso del heap máximo) o<=(en el caso del heap minimo) del que los valores de nodos hijos.
Usos
La estructura de árbol tiene varios usos, como algoritmos de tomada de decisión en aprendizaje de la maquina, indexación de banco de datos, indexación y exhibición de archivos y carpetas en el explorador de archivos de los sistemas operacionales. También, es usado en colas de prioridad (tipo especial de cola donde los elementos son retirados de la cola en el nodo padrón FIFO, pero si organizados por prioridad: más prioritarios en el inicio de la cola y menos prioritarios en el final) y también en un algoritmo de ordenación especifico, el heap sort.
Grafo
Otra estructura no lineal, el grafo (graph) es un conjunto de nodos (o vértices), ordenados o desordenados y conectados por aristas, formando una estructura en forma de red.
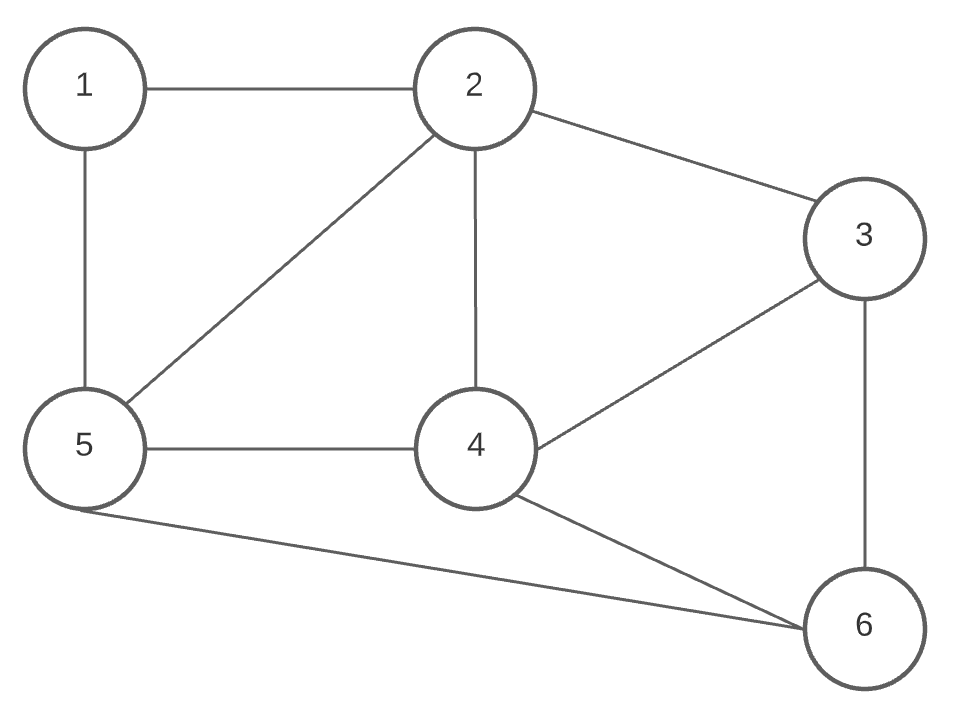
El grafo arriba puede ser representado de la siguiente forma: V = {1, 2, 3, 4, 5, 6} {los vértices o nodos} y E = {(1,2), (2,3),(3,4),(3,6),(4,2),(4,5),(5,1),(5,2),(5,6)} (las aristas o edges).
Cada una de las vertices del grafo pueden representar un tipo de dato o su referencia. Las aristas pueden ser no direccionadas como en el caso arriba, que no tienen una dirección definida, o direccionadas, como en el caso abajo:
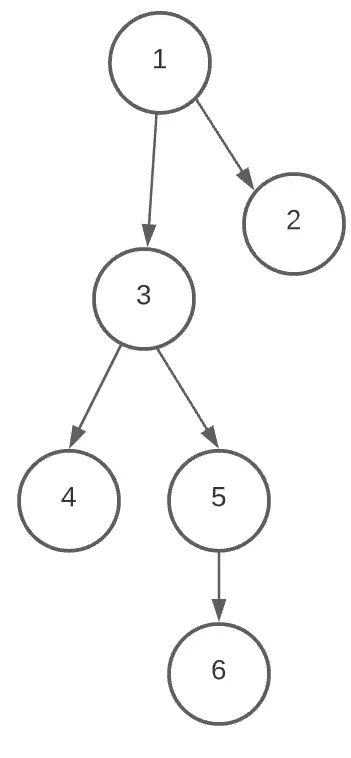
Las aristas de un grafo también pueden tener un valor (llamado de peso), que representan costo computacional, para cada "camino".
Usos
Las redes sociales utilizan los grafos para manejar una gran cantidad de datos relacionados entre si que reciben a cada instante. El ejemplo más famoso, la lenguaje de consulta GraphQL, fue creada por Facebook como el intuito de utilizar grafos para acceder y relacionar datos.
Otro uso famoso para los grafos es el sistema de la navegación de los aplicativos de mapas/GPS y el algoritmo de camino minimo (o shortest path) para definir caminos.
Conclusión
Como puedes haber percibido apenas una de cada estructura resumida podría tomar horas y horas de estudio para un entendimiento completo del paradigma por detras de cada una y para implementación de cada clase y método necesario. Varias estructuras ya tienen métodos y bibliotecas proprias implementadas en los diversos lenguajes más utilizados, pero es siempre interesante comprender lo que acontece "detrás de bastidores".
El estudio de estructura de datos, junto a su algoritmo, es parte esencial de los fundamentos de la programación. Es interesante combinar los estudios de estos temas con la practica haciendo proyectos, para ir añadiendo cada vez más conocimientos prácticos y teóricos.
Puedes empezar poco a poco, estudiando en profundidad cada una de las estructuras e investigando las posibles implementaciones en tu idioma preferido.
¡Buenos estudios!

Juliana Amoasei
Desarrolladora JavaScript con formación multidisciplinar, siempre aprendiendo a enseñar y viceversa. He estado involucrada en varias iniciativas de inclusión tecnológica desde 2018 y creo en el potencial del conocimiento como agente de cambio personal y social. Actualmente trabajo como instructor en la Escuela de Programación de Alura BR y doy tutoría técnica a principiantes en desarrollo web frontend y backend; fuera de la pantalla negra, me dedico al Kung Fu y a los nerds en general.
Este articulo fue adaptado y traducido por : Ingrid Pereira