

Cuando trabajamos con datos, especialmente en la fase de exploración de datos, realizamos muchos cambios en el dataset.
Hay columnas que no queremos, o que no necesitamos usar, o filas que no contienen datos válidos que deben eliminarse.
Pero, ¿cuánto más datos tenemos, no es mejor?
Cuando analizamos datos, principalmente para entrenar modelos de inteligencia artificial, algunos datos pueden perjudicar en lugar de ayudar. Por lo tanto, tenemos que usar solo los datos que tengan sentido para el modelo.
¡Excelente! Ya sabemos que necesitamos tratar los datos, pero ¿cómo podemos hacer eso, cómo eliminar los datos?
Eliminar columnas en pandas
Tengo un dataset sobre propinas que dan los usuarios a los taxistas. Vamos a utilizar Pandas para nuestro análisis, Pandas es una biblioteca que facilita la manipulación de datos. En Pandas, tenemos un tipo de dato llamado DataFrame. Podemos decir que un DataTrame es como una planilla de Excel. Es decir, tenemos filas y columnas.
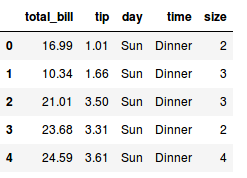
Vamos a realizar algunos análisis en nuestro dataset de propinas, llamado tips. Podemos ver el comienzo del contenido de la planilla utilizando el método head del data frame:
tips.head()
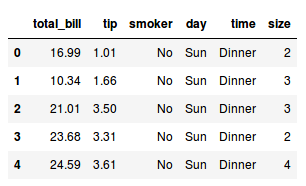
Podemos ver que el DataFrame se parece mucho a una planilla o a una tabla. Cada columna también conocida como variable tiene un nombre, y cada fila, conocida como observación, tiene un índice y los datos que representan cada variable.
Para el análisis que quiero hacer, no necesito saber si la persona fuma o no, por lo que no es necesario analizar la columna de smoker, ¿cómo podemos eliminarla?
En Pandas, hay un método drop para DataFrame. En este método, podemos pasar el índice de la fila que queremos eliminar:
>>> # en el
>>> tips.drop(2)
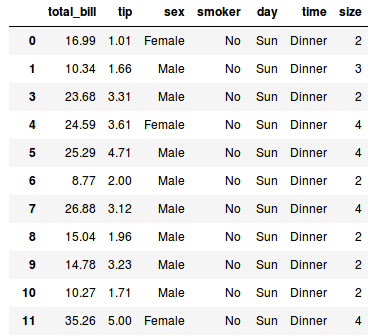
Con este comando, eliminamos la fila con índice 2. Pero en realidad no queremos eliminar una fila, sino una columna. Para hacer esto, simplemente pasamos el parámetro columns, este parámetro recibe una lista con el nombre de las columnas que queremos eliminar, smoker en nuestro caso.
Después de esto, mostramos nuevamente los datos:
tips.drop(columns = [‘smoker'])
tips.head()
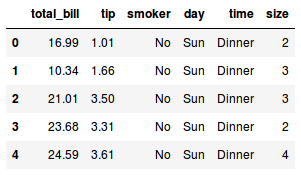
La columna sigue ahí. ¿Qué sucedió?
Por defecto, las operaciones que realizamos en un DataFrame no se aplican directamente en ese conjunto de datos. Es decir, cada vez que eliminamos una columna, fila, etc., lo que hace Pandas es devolver un nuevo DataFrame con los cambios aplicados. Es decir, el DataFrame original permanece intacto.
Lo que podemos hacer para resolver esto es asignar este nuevo DataFrame que el método drop() retorna a la misma variable tips:
tips = tips.drop(columnas = ['smoker'])
tips.head()
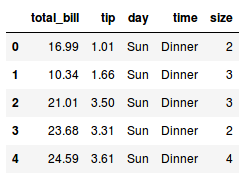
¡Super! Logramos eliminar la columna que necesitábamos. Ahora, pasemos a otra parte del procesamiento de datos. En el análisis que estoy haciendo, quiero analizar las propinas de aquellos recorridos donde hubo un grupos de pasajeros. Ese dato lo tenemos en nuestra columna size de nuestro DataFrame, se considera un grupo cuando en esta columna el valor es 2 o más.
¿Cómo podemos hacer para eliminar las filas que no cumplen con esta condición?
Eliminar filas
Sabemos que podemos usar el método drop() para eliminar una fila. Pero, ¿cómo eliminar todas las filas que contienen un solo pasajero?
Podemos recorrer e iterar a través de cada fila en el DataFrame y verificar si el número de pasajeros es mayor que uno. Si es así, conservamos esos datos, de lo contrario, los eliminamos del DataFrame.
Pero Pandas ya tiene varias formas de trabajar con DataFrames. Lo que podemos hacer es crear un filtro en el que se devuelva un nuevo DataFrame con los datos ya filtrados.
De la misma forma Pandas nos permite filtrar un DataFrame por sus datos de columna con condiciones en las filas. Por ejemplo, para el dataframe propinas (tips) capturamos la columna que define el número de pasajeros (size), en base a eso, filtramos las líneas en las que la columna size es mayor que uno:
filtro = tips['size'] > 1
Ahora, simplemente pasamos este filtro como selector en el DataFrame:
filtro = tips['size'] > 1
propina_en_grupo = tips[filtro]
Este filtro nos devuelve un DataFrame con todas las filas donde el número de pasajeros es mayor que 1. Es decir, los datos que pasan a través del filtro definido:
propinas_en_grupo.head()
Para saber más
Los filtros utilizados pueden ser más complejos. Podemos usar estructuras condicionales, como AND y OR, y verificar el valor de más de una columna. Además, podemos hacer otros tipos de filtros.
¿Cómo verificar si alguna fila tiene un valor nulo o un valor de un tipo diferente al esperado?. Para esto, se puede utilizar el concepto de rich comparison.
Además de la eliminación, podemos realizar otras operaciones con DataFrames, como ser: operaciones que involucran strings, renombrar columnas y agregar nuevas columnas, unir un DataFrame a otro, entre varias otras operaciones.
¿Qué tal aprender más sobre Pandas y sus diversos recursos? Entonces, ¡Mira nuestros cursos de Python para Data Science aquí en Alura!
Para seguir expandiendo tus conocimientos descarga nuestro ebook gratuito de Data Science a través del siguiente link: https://lp.caelum.com.br/alura-latam-leads-ebook-data-science
