Ampliando el análisis con Describe

Introducción
Normalmente realizamos cálculos estadísticos para obtener insights durante el análisis exploratorio de los datos. Para facilitar nuestro trabajo, podemos recurrir al uso de diversas herramientas, como por ejemplo Microsoft Excel e incluso lenguajes de programación como R, Python y sus bibliotecas.
¡La biblioteca Pandas es una de ellas! Llena de funciones orientadas a todo tipo de necesidades, incluyendo métodos que pueden facilitarnos la vida. Al momento de describir estadísticamente una base de datos, por ejemplo, la función describe es capaz de generar estadísticas descriptivas a partir de una base de datos importada.
Leyendo la base de datos
Utilizaremos un conjunto de datos de recursos humanos para comprender mejor el funcionamiento de esta función. Importaremos el archivo CSV que contiene la base de datos y mostraremos las primeras 5 filas utilizando la función head().
import pandas as pd
datos = pd.read_csv("/content/HRDataset_v14.csv")
datos.head()
Hecho esto, podemos observar que la base importada posee datos categóricos y numéricos. Así, vamos a utilizar la función describe para comprender cuáles resultados serán retornados.
Datos numericos
datos.describe()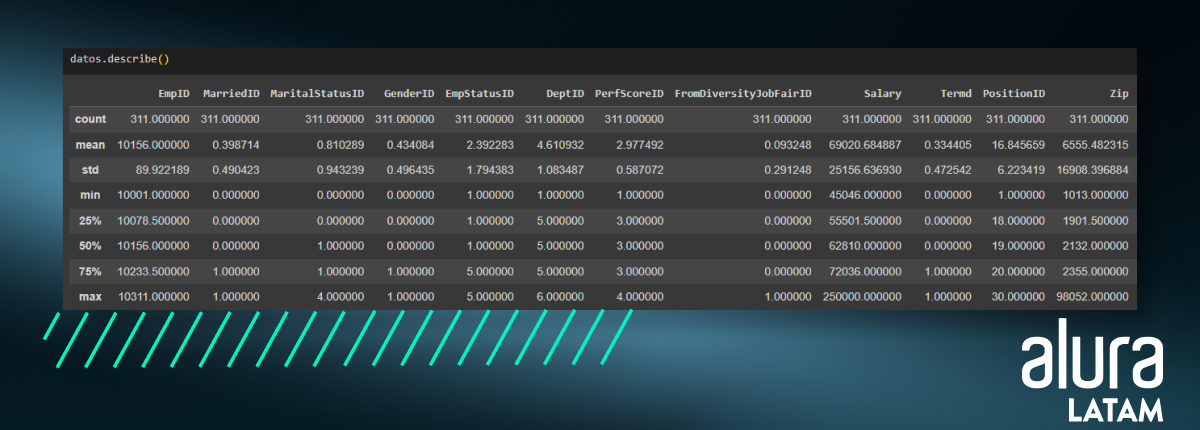
Nótese que la función describe, por defecto, selecciona solo los datos numéricos, devolviendo el conteo de filas (count), el cálculo de la media (mean), el desvío estándar (std), e identifica el valor mínimo (min), los cuartiles (25%, 50% y 75%), y el valor máximo (max).
Para que podamos tener un mejor entendimiento de los resultados, enfoquémonos en la columna Salary (salario, en español).
- count - A través del conteo de valores, podemos comprender el tamaño de la muestra. También es posible detectar filas con valores vacíos comparando el valor de
countentre dos columnas. Imagina que usaste la funcióndescribey la columna ID tiene 500 valores, pero la columna Salary tiene 300 valores. Con esto, sabemos que la columna Salary tiene 200 valores vacíos, y es necesario tratar estos datos. - mean - Siendo la media aritmética, siempre debemos prestar atención a lo que representa, ya que el resultado no siempre refleja la realidad. Podemos pensar en una muestra del salario mensual de 5 personas, de las cuales 4 reciben 2.000 dólares y una recibe 50.000 dólares. Al calcular la media simple, obtenemos 11.600 dólares como resultado, lo cual no representa la realidad de la mayoría de las personas en esta muestra.
- std - El desvío estándar es una medida de cómo los datos se dispersan en relación con la media. En otras palabras, muestra cuán dispersos están los datos. El desvío estándar es la estadística descriptiva que nos permite asignar un número único a esta dispersión en torno a la media. Si la distribución es muy dispersa, podemos calcular cuántos desvíos estándar se aleja del centro. En nuestro caso, sabemos que aproximadamente 25 mil dólares varían en torno a la media.
- min y max - Son valores que nos ayudan a identificar la amplitud de la muestra. En la columna Salary, tenemos una persona que recibe aproximadamente 45 mil dólares (
min) y otra que recibe aproximadamente 250 mil dólares (max). Entonces, la amplitud es igual a la diferencia entre 250 mil y 45 mil. - cuartiles - Son valores que nos muestran cómo se distribuyeron los datos. Por ejemplo, el cuartil del 50%, definido como mediana, en el caso de la columna Salary, indica que la mitad de los valores son inferiores a 62 mil dólares y la otra mitad son superiores a 62 mil dólares.
Datos categóricos
También es posible obtener algunas informaciones de las columnas categóricas. Para ello, necesitamos seleccionarlas para usar la función describe.
datos[["State","Sex"]].describe()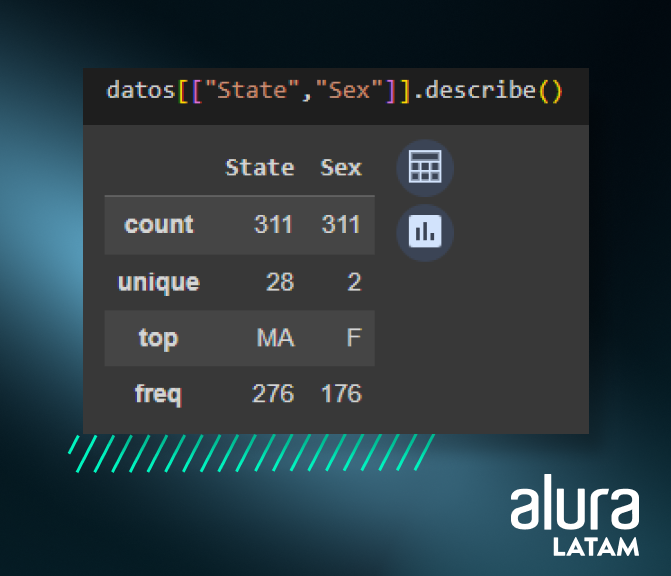
Como los datos de las columnas State y Sex son categóricos, la función describe retorna cálculos más adecuados para este tipo de datos, como el conteo de valores distintos (unique), la moda (top) y la frecuencia de la misma (freq). Por ejemplo, la moda MA, que tiene una frecuencia superior al 50% de toda la muestra.
Si tienes interés en conocer aún más sobre esta función y su aplicabilidad, te invito a leer la documentación.
Dejo el repositorio completo aquí en GitHub.
Este articulo fue traducido y adaptado por Ingrid Silva
David Neves Con una trayectoria versátil que abarca front-end, back-end e infraestructura, descubrí mi pasión por desvelar el potencial de los datos. Hoy, como especialista en Business Intelligence, con enfoque en Power BI, encuentro mi motivación en la difusión de conocimiento de alta calidad.